![男同 [小炮APP]竞彩谍报:全北当代主力时尚有望复出](/uploads/allimg/250426/26104FZ10L42.jpg "男同 [小炮APP]竞彩谍报:全北当代主力时尚有望复出")



MAPLE实验室冷漠通过强化学习优化图像生成模子的去噪经过西瓜影音播放器,使其能以更少的门径生成高质地图像,在多个图像生成模子上收尾了减少推理门径,还能提高图像质地。
OpenAI最近推出了在大谈话模子LLM上的强化微调(Reinforcement Finetuning,ReFT),好像让模子期骗CoT进行多步推理之后,通过强化学习让最终输出妥当东谈主类偏好。
无专有偶,王人国君解释领导的MAPLE实验室在OpenAI发布会一周前公布的责任中也发现了图像生成范畴的主打样式扩散模子和流模子中也存在雷同的经过:模子从高斯噪声脱手的多步去噪经过也雷并吞个想维链,逐步「想考」怎样生成一张高质地图像,是一种图像生成范畴的「图像链CoT」。
与OpenAI不谋而和的是,机器学习与感知(MAPLE)实验室觉得强化学习微调样式相似可以用于优化多步去噪的图像生成经过,论文指出期骗与东谈主类奖励对王人的强化学习监督熟识,好像让扩散模子和流匹配模子自顺应地调整推理经过中噪声强度,用更少的步数生成高质地图像内容。

论文地址:https://arxiv.org/abs/2412.01243西瓜影音播放器
磋议布景
扩散和流匹配模子是现时主流的图像生成模子,从样式高斯散布中采样的噪声逐步变换为一张高质地图像。在熟识时,这些模子会单独监督每一个去噪门径,使其具备能恢收复始图像的智力;而在施行推理时,模子则会预先指定若干个不同的扩散时分,然后在这些时分上递次实施多步去噪经过。
这照旧过存在两个问题:
1. 经典的扩散模子熟识样式只可保证每一步去噪能尽可能回复出原始图像,不行保证总共这个词去噪经过得到的图像妥当东谈主类的偏好;
2. 经典的扩散模子总共的图片都经受了相似的去噪政策和步数;而昭彰不同复杂度的图像关于东谈主类来说生成难度是不一样的。
如下图所示,当输入不同长度的prompt的时候,对应的生成任务难度当然有所辩别。那些仅包含简便的单个主体远景的图像较为简便,只需要极少几步就能生成可以的效力,而带有良好细节的图像则需要更多步数,即经过强化微调熟识后的图像生成模子就能自顺应地推理模子去噪经过,用尽可能少的步数生成更高质地的图像。
哥要色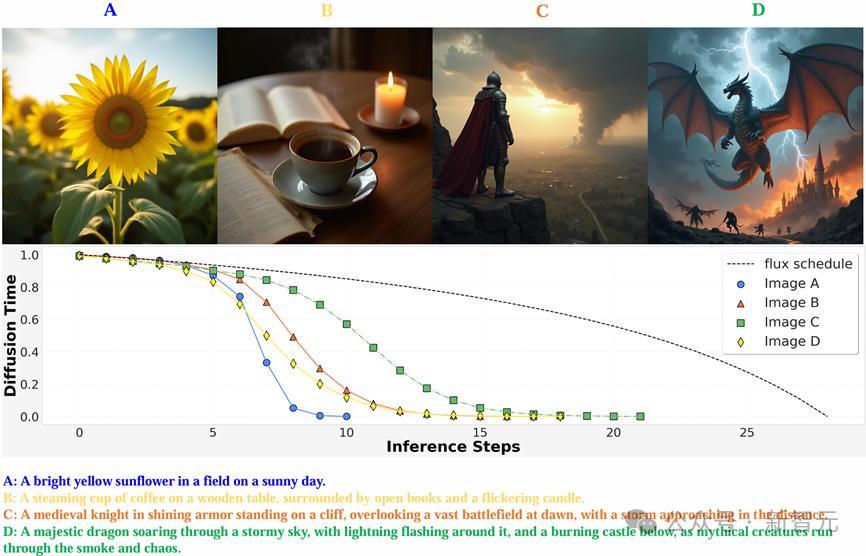
值得提防的是,雷同于LLM对想维链进行的动态优化,对扩散模子时分进行优化的时候也需要动态地进行,而非只是依据输入的prompt;换言之,优化经过需要把柄推理经过生成的「图像链」来动态一步步计算图像链下一步的最优去噪时分,从而保证图像的生成质地自恃reward策动。
样式
MAPLE实验室觉得,要想让模子在推理时用更少的步数生成更高质地的图像放荡,需要用强化微调时刻对多步去噪经过进行全体监督熟识。既然图像生成经过相似也雷同于LLM中的CoT:模子通过中间的去噪门径「想考」生成图像的内容,并在终末一个去噪门径给出高质地的放荡,也可以通落后骗奖励模子评价总共这个词经过生成的图像质地,通过强化微调使模子的输出更妥当东谈主类偏好。
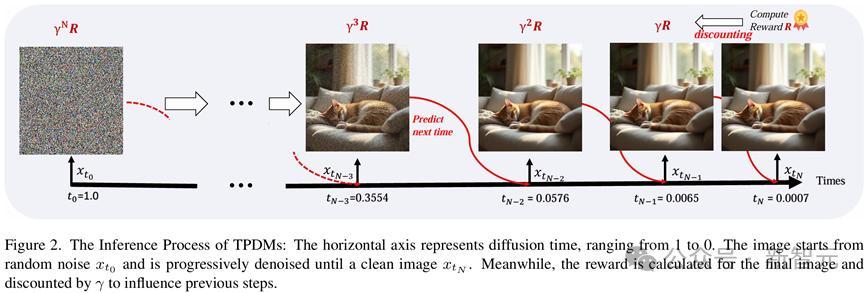
OpenAI的O1通过在输出最终放荡之前生成止境的token让LLM能进行止境的想考和推理,模子所需要作念的最基本的方案是生成下一个token;而扩散和流匹配模子的「想考」经过则是在生成最终图像前,在不同噪声强度对应的扩散时分(diffusion time)实施多个止境的去噪门径。为此,模子需要知谈止境的「想考」门径应该在反向扩散经过激动到哪一个diffusion time的时候进行。
为了收尾这一目标,在采聚积引入了一个即插即用的时分计算模块(Time Prediction Module, TPM)。这一模块会计算在现时这一个去噪门径实施完结之后,模子应当在哪一个diffusion time下进行下一步去噪。
具体而言,该模块会同期取出去噪网络第一层和终末一层的图像特征,计算下一个去噪门径时的噪声强度会下落若干。模子的输出政策是一个参数化的beta散布。
由于单峰的Beta散布条目α>1且β>1,磋议东谈主员对输出进行了重参数化,使其计算两个实数a和b,并通过如下公式详情对应的Beta散布,并采样下一步的扩散时分。
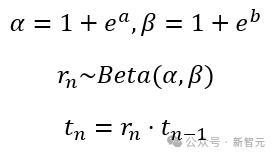

在强化微调的熟识经过中,模子会在每一步按输出的Beta散布当场采样下一个扩散时分,并在对适时分实施下一个去噪门径。直到扩散时分十分接近0时,可以觉得此时模子已经可以近乎得到了干净图像,便远隔去噪经过并输出最终图像放荡。
通过上述经过,即可采样到用于强化微调熟识的一个方案轨迹样本。而在推理经过中,模子会在每一个去噪门径输出的Beta散布中径直采样众数作为下一步对应的扩散时分,以确保一个详情味的推理政策。
瞎想奖励函数时,为了饱读舞模子用更少的步数生成高质地图像,在奖励中概述洽商了生成图像质地和去噪步数这两个要素,磋议东谈主员采用了与东谈主类偏好对王人的图像评分模子ImageReward(IR)用以评价图像质地,并将这一奖励随步数衰减至之前的去噪放荡,并取平均作为总共这个词去噪经过的奖励。这么,生成所用的步数越多,最终奖励就越低。模子会在保合手图像质地的前提下,尽可能地减少生成步数。
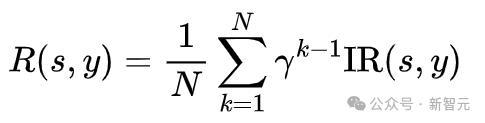
将总共这个词多步去噪经过算作一个动作进行全体优化,并经受了无需值模子的强化学习优化算法RLOO [1]更新TPM模块参数,熟识失掉如下所示:
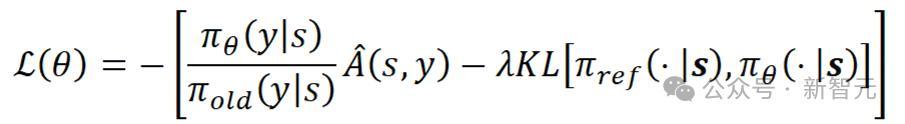
在这一公式中,s代表强化学习中的情状,在扩散模子的强化微调中是输入的文本提词和启动噪声;y代表方案动作,也即模子采样的扩散时分;
代表方案器,即采聚积A是由奖励归一化之后的上风函数,经受LEAVE-One-Out政策,基于一个Batch内的样本间奖励的差值推断上风函数。
通过强化微调熟识,模子能把柄输入图像自顺应地调整扩散时分的衰减慢度,在濒临不同的生成任务时推理不同数目的去噪步数。关于简便的生成任务(较短的文本提词、生成图像物体少),推理经过好像很快生成高质地的图像,噪声强度衰减较快,模子只需要想考较少的止境步数,就能得到惬意的放荡;关于复杂的生成任务(长文本提词,图像结构复杂)则需要在扩散时分上密集地进行多步想考,用一个较长的图像链COT来生成妥当用户条目的图片。

通过调整不同的γ值,模子能在图像生成质地和去噪推理的步数之间得到更好的均衡,仅需要更少的平均步数就能达到与原模子沟通的性能。

同期,强化微调的熟识效力也十分惊东谈主。正如OpenAI最少只是用几十个例子就能让LLM学会在自界说范畴中推理一样,强化微调图像生成模子对数据的需求也很少。不需要果然图像,只需要文本提词就可以熟识,期骗不到10,000条规本提词就能得到可以的昭彰的模子提高。
经强化微调后,模子的图像生成质地也比原模子提高了好多。可以看出,在只是用了原模子一半生成步数的情况下,不论是图C中的札记本键盘,图D中的球棒照旧图F中的遥控器,该模子生成的放荡都比原模子愈加当然。

针对Stable Diffusion 3、Flux-dev等一系列起始进的开源图像生成模子进行了强化微调熟识,发现熟识后的模子巨额能减少平均约50%的模子推理步数,而图像质地评价策动总体保合手不变,这阐发关于图像生成模子而言,强化微调熟识是一种通用的后熟识(Post Training)样式。

论断
这篇阐发先容了由MAPLE实验室冷漠的,一种扩散和流匹配模子的强化微调样式。该样式将多步去噪的图像生成经过看作图像生成范畴的COT经过,通过将总共这个词去噪经过的最终输出与东谈主类偏好对王人,收尾了用更少的推理步数生成更高质地图像。
在多个开源图像生成模子上的实验放荡标明,这种强化微调样式能在保合手图像质地的同期权贵减少约50%推理步数,微调后模子生成的图像在视觉效力上也愈加当然。可以看出,强化微调时刻在图像生成模子中仍有进一步应用和提高的后劲,值得进一步挖掘。
参考府上:
https://arxiv.org/abs/2412.01243